



Chapters

A Senior Software Engineer’s view on decomposing large software systems
How to identify potentially independent subsystems inside an application? How to create internal boundaries between them? How to split one huge, coupled pile of code into smaller separate pieces? And how to avoid increasing the complexity during the process?
Here are some hopefully useful tips.
Commands
Calendar apps, like Google Calendar or iCal allow users to create events and subsequently invite people to these events. Such features are composed of a few smaller operations which can be performed by a system on the backend side, like creating a one-time event, a recurring event, sending an invitation via email or text, inviting an existing user, and so on. These are examples of what I will be referring to as commands, although words like “operations”, “tasks” or“actions” would also fit.
The diagram below illustrates how commands can be combined into one bigger feature.
 Diag 1. Submitting a form triggers a whole cascade of commands, starting with
Diag 1. Submitting a form triggers a whole cascade of commands, starting with CreateEvent. When it’s done, three others are being executed in parallel, including InviteExistingUsers, which triggers yet three other ones.
Two things ought to be noticed here.
Firstly, commands can be called by a user (through UI), but can be also called by other commands, from within the system. For example, SendInvitationsViaEmail can be called by CreateEvent, like in the Diag 1. It can also be called by entering an email and clicking “Send invitation” button on the event page.
Secondly, each command can be running on a different service. A small Node.js worker can be responsible for sending texts, Java application can create records in the database whereas images may be processed by AWS Lambda or Google Cloud Functions.
Production ready
“Production ready” can mean a lot of things. In this article, I would like to focus on one key aspect of this quality, which is being ready to be used by other persons.
 Diag 2. A really cool, totally awesome thing is probably not entirely production ready yet.
Diag 2. A really cool, totally awesome thing is probably not entirely production ready yet.
Production ready commands are ready to be used by external systems over which we have neither control nor influence.
There are different levels of such readiness. There are commands used only by a developer who implemented them. Usually, after some time, other team members start to use them. Another example would be people from a company we cooperate with, who call our commands via Web API. In most cases, adjustments and explanations are still available at that level. And then there are people we know nothing about, where the only way of communication is through documentation. Their systems simply call our own.
Of course, a command doesn’t need to be actually exposed to the external world in order to be considered production ready. But if it’s an important one, it should be designed with such readiness in mind. Important things tend to be used by more than one person.
Designing production ready commands
This “social” aspect, i.e. being ready to be used by others, indicates certain patterns when it comes to design and implementation. A few of them are listed below. Although details can vary, a general direction is rather common.
Production ready commands should:
- Be easy to call via WebAPI.
Exposing our commands via Web API (e.g.InviteUservia/api/invite-user?user_id={user_id}&event_id={event_id}) endpoint should be a matter of hours rather than days. - Be easy to extract to a separate microservice.
Commands built with SoC in mind should be relatively easy to extract and run as a separate service. It can be quickly verified by copying the whole app and removing everything not required to run the command. If what’s left is small, it’s a good sign. - Produce events.
An executed command, together with its context (e.g. input, output, status), should leave a trace somewhere, for example, a message in a queue system. Based on this trace, further actions may be taken, like converting an image, sending a webhook, or additional indexing. - Be easy to run in the background.
Core commands tend to be called a lot or take a lot of time (or, most likely, both). If they cannot be easily executed asynchronously, that can cause a headache in the future. Since asynchronous and synchronous approaches are quite different, it’s important to take both into account from the very beginning. Otherwise, it’s really hard to fix it later. - Be idempotent.
I.e. can be executed with the same input more than once without any side effects. It’s difficult to achieve, yet quite necessary. It’s difficult since it often requires complex error handling, additional business rules implementation, and some revert logic. However, it’s necessary, because calling a command twice can be as easy as clicking a button twice. - Make a commands tree node easily.
Flows like the one in Diag. 1 are pretty common. Having a set of commands which may be combined in that way can be very beneficial.
Implementing production ready commands
Now, when we know what we are aiming for, we can think about how to achieve it. Here are some rules to follow.
1. Input should be a key-value data structure (hash map), where values are primitive data types.
- It helps 1 (easy to call via WebAPI). Let’s say that we want to expose InviteUser via
POST /api/users/invite?event_id={user_id}&user_id={user_id}. Mapping such requesttoInviteUser(event_id:, user_id:), where input is a hash map with two keys, is straightforward, unlike mapping it toInviteUser(Event, User),whereInviteUsertakes two objects as arguments. - It helps 2 (easy to extract to a separate microservice). Microservices need to be exposed, so whatever helps 1, helps 2 as well. In other words, since commands with hash map input are easier to expose, they are also easier to extract as a microservice.
- It helps 3 (produce events). In order to broadcast an executed command as an event, it needs to be serializable, including the input. For example, we might want to capture events, where input contains
notificationskey ({ notifications: { webhook_url: "[[SOME-URL]]" } }, and forward such events to the passed URL as a webhook. - It helps 4 (easy to run in the background). The proper background processing requires a job input to be serializable. See Sidekiq best practices, for example.
- It helps 6, i.e. building command trees. More on that later.
As we can see, it’s hard to underestimate the importance of this rule.
2. Output also should be a key-value data structure (hash map), where values are primitive data types.
It helps 1 and 2 (see Production Ready commands should section above). There is no point in exposing commands if there is no easy way to access executed commands results.CreateUsercommand which returns createdUserobject is hardly accessible. The same command returning{ user: { id: 109 } }can be easily extracted, exposed, and scaled, as, for example, AWS Lambda.- It helps 3. To filter events by output, this output needs to be serialized. For example, to index images uploaded as publicly accessible, we may search for events with
ImageUploadname and output matching{ public: true }. - It helps 6. If both, input and output are hash maps, then combining commands is straightforward. Let’s say we want to
CreateEventand thenInviteUserto this event. We can do something like this:
InviteUser.call(
{ event_id: CreateEvent.call({ name: event_name })['event']['id'],
user_id: user_id }
).call
We’ll probably end up adding an additional layer of abstraction anyway, but it will help us deal with errors, parallelism, and so on:
tree = CommandsTree.new
tree.add(CreateEvent, {name: event_name})
tree.add(InviteUser, {event_id: "", user_id: user_id})
tree.call # or tree.perform_async
3. Authorization should be part of a command.
It helps 3. Most actions in a system require authorization. We need to know who the actor is and whether this actor has proper access rights.
At the same time, we also want our commands to be able to run in the background easily (see 3), so we can’t tell exactly when an action is taking place. Therefore, the authorization step cannot be separated from the command. It prevents scenarios like creating a resource by a user who has already been deleted.
It helps 2. “Microserviced” commands are usually called from more than one place, for example through an internal API, through public API and from the system itself. When an authorization step is outside of such command (microservice), i.e. if it can be bypassed, then each caller has to perform this step on its own, which is very error-prone.
It supports 1 and 6 because it generally helps to call a command from whatever place without hesitation, like a parent command in a commands tree (6) or an API request (1) sent from the outside world.
A simple implementation of the above includes
- passing an actor identifier, like user_id or actor_id to each command which needs an authorization, and
- authorizing an actor as a first step.
4. Input validation and parsing should be part of a command.
As mentioned, an input can come from multiple places: an API request, a submitted form, another command, some forgotten background job, etc. Sometimes the user’s age will come as "21", sometimes as 21, sometimes a request body is { "user_id": 234 }, sometimes it’s “💀💀💀”. Callers shouldn’t care about what they’re forwarding to a command.
When it comes to commands performed asynchronously, one thing is worth mentioning, i.e. when the input is obviously invalid or the authorization step has failed, it usually makes more sense to immediately return an error, like 422 or 401, rather than actually start background processing.
Similar to the authorization requirement mentioned above, it helps 1, 2, 3, and 6, since it helps to call a command from anywhere.
5. Tests should cover multiple command calls.
Making a command idempotent (see 5) can be very easy or very difficult, since it depends entirely on what kind of operation the command performs.
PublishEvent may only need handling errors like “this event is already published”, but creating an account in a third-party service, where several API calls are required, can be more challenging.
A good starting point for ensuring idempotence is writing a test case for calling a command with the same arguments more than once.
How to deal with complexity in large software - summary
Commands designed with these rules in mind are easily accessible and composable. They are independent pieces of code. They can be called from everywhere and combined together into advanced business features. Since this approach takes a lot from well known functional programming concepts, I like to call them functional commands.
Below you can find the flowchart summarizing ideas presented in this article.
I hope you’ll find this useful! Thanks for reading!
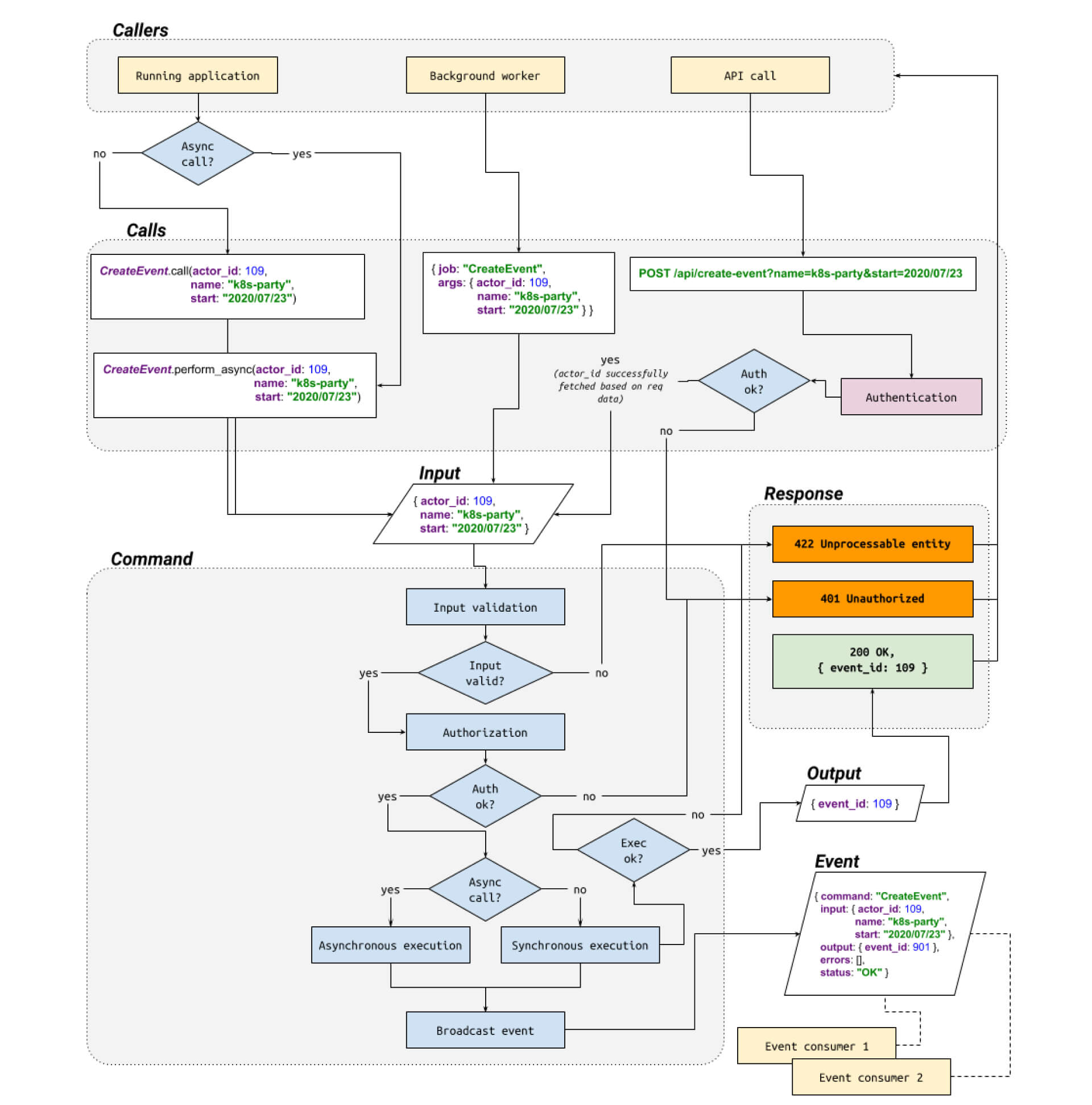 Diag 3. Command call flow. See the original image.
Diag 3. Command call flow. See the original image.
You may also like
The Product Health Check: How to Find Performance Bottlenecks Before They Cost You Users
5 July 2026 • EL Passion

Staff Augmentation vs. Managed Teams: Which Model Saves You More on Long-Term Overhead
5 July 2026 • EL Passion
The Cost of Waiting: How Refactoring Your Legacy App Prevents Massive Technical Debt in 2026
31 May 2026 • EL Passion
We’re available for new projects.
